GLM-4.7: The Open-Source LLM That Codes Like a Pro
Z.ai GLM-4.7 is a powerful open-source AI model with advanced reasoning, huge context windows, and top-tier coding performance at low cost.

Sohail Shaikh
Author

GLM-4.7: The Open-Source LLM That Codes Like a Pro
December 22, 2025. That's when everything changed for developers looking for an affordable, powerful coding assistant.
I remember opening Twitter that morning and seeing the flood of benchmarks. GLM-4.7 hitting 73.8% on SWE-bench Verified. A massive 12.9% jump in multilingual coding performance. Terminal tasks improving by 16.5%. Numbers that made me immediately stop what I was doing and dive in.
After two weeks of testing GLM-4.7 in real projects—building web apps, debugging legacy code, automating workflows—I can tell you this: this isn't just another incremental model release with slightly better benchmarks. This is the open-source coding assistant that finally feels like it was built for actual developers, not just demos.
Let me show you why GLM-4.7 matters, and more importantly, how you can start using it today.
What is GLM-4.7?
GLM-4.7 is Zhipu AI's latest flagship foundation model featuring a 200K context window, 128K output capacity, and a sophisticated Mixture-of-Experts (MoE) architecture. But here's what that actually means in practice:
It's a coding model that thinks. Not in the gimmicky "watch me solve FizzBuzz" way. In the "I'm going to maintain context across 20 turns of debugging, remember the architecture decisions we discussed earlier, and not contradict myself halfway through" way.
Released under an MIT License with 358 billion total parameters, GLM-4.7 is the kind of model you can actually use in production without worrying about vendor lock-in or surprise pricing changes. It's freely accessible and delivers quality outputs comparable to proprietary models like Claude Sonnet 4.5 and GPT-5, but at a fraction of the cost.
Here's the kicker: it was trained with the assumption that it will live inside terminals, agent loops, and long, messy sessions—not chat demos. You can feel that in every interaction.
Key Features That Make GLM-4.7 Stand Out
1. Thinking Modes That Actually Work
Most models claim to "think" before they act. GLM-4.7 actually does it, and gives you control over how and when.
Interleaved Thinking: The model thinks before every response and tool call, improving instruction following and generation quality.
Preserved Thinking: In coding agent scenarios, GLM-4.7 automatically retains all thinking blocks across multi-turn conversations, reusing existing reasoning instead of re-deriving from scratch. This is huge for complex, long-horizon tasks where context matters.
Turn-level Thinking: You can disable thinking for lightweight requests to reduce latency and cost, then enable it for complex tasks to improve accuracy and stability.
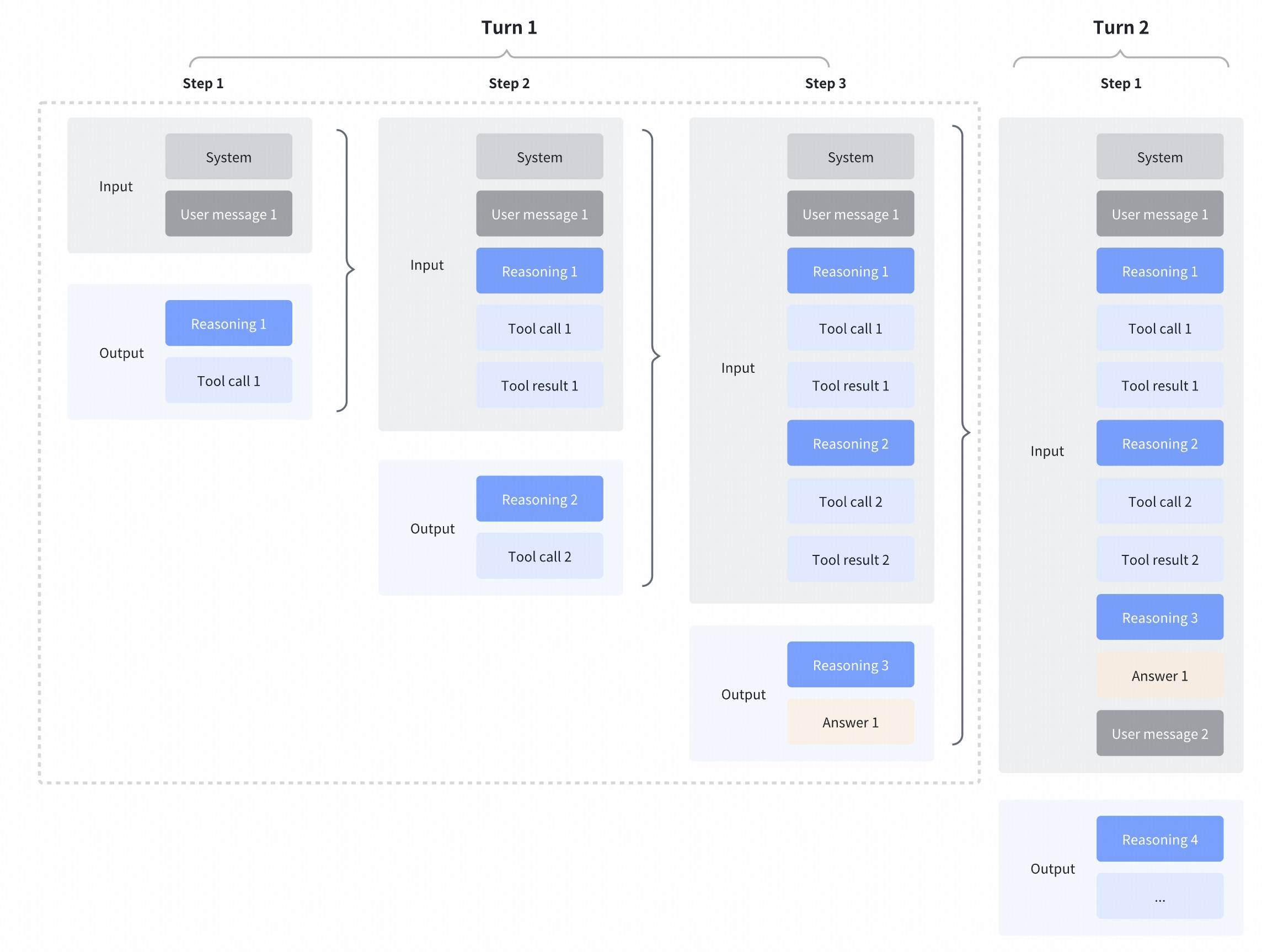
I tested this by building a full-stack app over multiple sessions. The model remembered architectural decisions from session one when I came back three days later to add authentication. That never happens with most models—they usually treat each session like you're starting from scratch.
2. Vibe Coding: UI That Doesn't Look Like It's From 2010
This feature deserves its own section because it's genuinely surprising.
GLM-4.7 takes a major step forward in UI quality, producing cleaner, more modern webpages and generating better-looking slides with more accurate layout and sizing.
I asked it to build a landing page with "dark mode, bold typography, and animated elements." What it generated wasn't just functional—it looked good. Modern gradients, proper spacing, smooth animations, responsive design that actually works. The kind of output that makes you think "I could ship this" rather than "I need to completely rewrite this."
Try asking Claude or GPT-4 to build a modern UI and you'll appreciate the difference. GLM-4.7 understands contemporary design patterns in a way that feels almost uncanny.
3. Multilingual Coding That Actually Works
GLM-4.7 achieves 66.7% on SWE-bench Multilingual, a massive +12.9% improvement over GLM-4.6.
This isn't just about translating code comments. It's about understanding mixed-language codebases, handling non-English variable names gracefully, and generating documentation that makes sense in multiple languages.
If you're working on international projects or maintaining codebases with mixed-language conventions, this is a game-changer.
4. Terminal and Tool Use That Doesn't Panic
GLM-4.6 scored a painful 24.5% on Terminal Bench 2.0. GLM-4.7 jumps to 41.0%—a +16.5% improvement.
What does this mean in practice? The model retries commands more sensibly, doesn't hallucinate successful operations, and actually recovers from failures instead of giving up or spiraling into confusion.
Commands are sequenced correctly, state is maintained, and recovery logic is significantly stronger. This is the difference between a demo that impresses in screenshots and an agent you can actually leave running while you grab coffee.
5. Massive Context: 200K In, 128K Out
GLM-4.7 supports a 200,000-token context window with a maximum output capacity of 128,000 tokens.
You can feed it entire codebases, comprehensive documentation, or long conversation histories. And critically, it can generate entire software modules in a single response without truncating halfway through a function.
I tested this by feeding it a 15,000-line legacy Python codebase and asking for a complete refactoring plan. It analyzed the entire thing, identified architectural issues, and proposed solutions that demonstrated understanding of the whole system, not just individual files.
Benchmarks & Performance Improvements
Let me show you the numbers that matter:
Coding Performance
| Benchmark | GLM-4.6 | GLM-4.7 | Improvement |
|---|---|---|---|
| SWE-bench Verified | 68.0% | 73.8% | +5.8% |
| SWE-bench Multilingual | 53.8% | 66.7% | +12.9% |
| Terminal Bench 2.0 | 24.5% | 41.0% | +16.5% |
These aren’t incremental “+0.3% on obscure benchmarks” improvements. These are meaningful gains on benchmarks that measure real-world coding ability.
Reasoning & Tool Use
GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving 42.8% on the HLE (Humanity's Last Exam) benchmark compared to 30.4% in GLM-4.6—a +12.4% improvement.
On τ²-Bench, GLM-4.7 scores 87.4% compared to 75.2% in 4.6. This benchmark exposes planning errors, not just knowledge gaps. GLM-4.7 plans better, period.
BrowseComp scores went from 45.1% to 52.0%, and with context management enabled, 67.5%. The model can carry forward what it read earlier instead of re-summarizing like it has amnesia.
How It Compares to Frontier Models
Here's how GLM-4.7 stacks up against the big names:
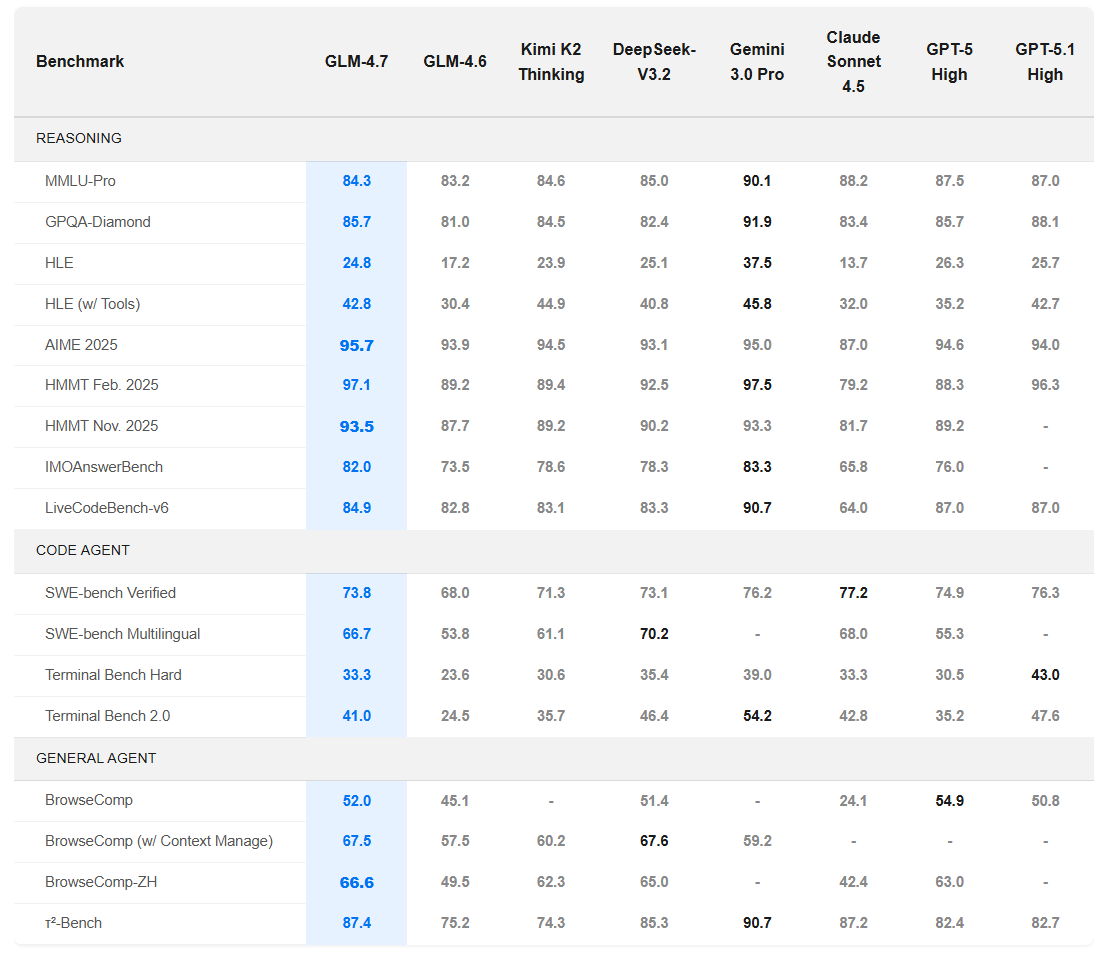
GLM-4.7 is trading blows with models that cost 5–10× more. In Code Arena’s blind evaluation, it ranked first among open-source models.
Use Cases — Who Should Care?
Individual Developers & Freelancers
If you're paying $20-30/month for Claude or GPT-4 access primarily for coding, GLM-4.7 could save you serious money. Pricing is set at roughly $0.60 per 1 million input tokens and $2.20 per 1 million output tokens—significantly cheaper than proprietary alternatives.
Best for:
- Building side projects and MVPs
- Learning new frameworks and languages
- Code reviews and refactoring
- Generating boilerplate and documentation
Startups & Small Teams
Z.ai offers GLM Coding Plans that provide access to a Claude-level coding model at just 1/7th the price with 3x the usage quota.
For resource-conscious startups, this is a no-brainer. You get frontier-model performance without the frontier-model bill.
Best for:
- MVP development with limited budgets
- Internal tooling and automation
- Technical documentation generation
- Code review automation
Enterprise Developers
GLM-4.7 offers a Context Caching mechanism where cached input tokens are billed at a significantly reduced rate (approximately $0.11 per 1M tokens), reducing total costs by 20-40% for heavy-duty applications.
For large organizations with substantial AI usage, the cost savings compound quickly. Plus, the MIT License means you can self-host, fine-tune, and customize without licensing concerns.
Best for:
- Large-scale code generation pipelines
- Internal AI coding assistants
- Legacy codebase modernization
- Multi-language development environments
Researchers & Students
The combination of being open-source, affordable, and highly capable makes GLM-4.7 perfect for academic use.
Best for:
- Research on code generation
- Fine-tuning experiments
- Educational applications
- Prototyping AI-powered dev tools
How to Try GLM-4.7
Let's get practical. Here are the three main ways to use GLM-4.7:
1. Chat Interface (Easiest Start)
Z.ai Chat Interface
🔗 https://chat.z.ai
This is your quickest path to trying GLM-4.7. Just sign up and start chatting. Perfect for:
- Testing the model's capabilities
- Quick coding questions
- Prototyping ideas
- Generating code snippets
No setup required. Just open the browser and go.
2. Coding Agents (Best for Development)
GLM-4.7 works seamlessly with mainstream agent frameworks including Claude Code, Kilo Code, Cline, and Roo Code.
Claude Code Setup:
# Update your ~/.claude/settings.json
{
"model": "glm-4.7",
"api_endpoint": "https://api.z.ai/v1"
}
If you're subscribed to GLM Coding Plan, you'll be automatically upgraded to GLM-4.7.
Why use coding agents?
- Native terminal integration
- File system access
- Multi-step task execution
- Persistent context across sessions
This is where GLM-4.7 really shines. The preserved thinking mechanism works beautifully in these environments.
3. API Integration (For Production)
Z.ai API Platform
🔗 https://docs.z.ai/guides/llm/glm-4.7
OpenRouter (Multi-Provider Access)
🔗 https://openrouter.ai/z-ai/glm-4.7
Here's a quick Python example using the OpenAI SDK format:
from openai import OpenAI
# Via Z.ai
client = OpenAI(
api_key="your-zai-api-key",
base_url="https://api.z.ai/v1"
)
# Or via OpenRouter
client = OpenAI(
api_key="your-openrouter-api-key",
base_url="https://openrouter.ai/api/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{"role": "system", "content": "You are an expert Python developer."},
{"role": "user", "content": "Write a function to parse JSON with error handling"}
],
max_tokens=2000,
temperature=0.7
)
print(response.choices[0].message.content)
Enable thinking mode for complex tasks:
response = client.chat.completions.create(
model="glm-4.7",
messages=[...],
extra_body={
"thinking_mode": "enabled", # Enable interleaved thinking
"preserve_thinking": True # Preserve across turns
}
)
4. Local Deployment (Full Control)
Hugging Face
🔗 https://huggingface.co/zai-org/GLM-4.7
For local deployment, GLM-4.7 supports inference frameworks including vLLM and SGLang.
# Install vLLM
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
# Run GLM-4.7
vllm serve zai-org/GLM-4.7 \
--dtype auto \
--max-model-len 32768
Or with Ollama:
ollama pull glm-4.7
ollama run glm-4.7
🔗 https://ollama.com/library/glm-4.7
Local deployment gives you:
- Complete data privacy
- No API costs
- Unlimited usage
- Custom fine-tuning capability
Pros, Cons & Real-World Considerations
Let me give you the unvarnished truth after two weeks of real use.
The Good Stuff ✅
1. Cost-Effectiveness is Real
At approximately $0.11 per million input tokens and $2.20 per million output tokens (with caching), this is legitimately affordable for production use.
For context: analyzing a 10,000-line codebase costs about $0.03. Compare that to Claude Sonnet 4.5's pricing, and the savings add up fast.
2. The Thinking Mechanism Works
Preserved Thinking reduces information loss and inconsistencies in coding agent scenarios. In practice, this means the model doesn't contradict itself or forget context after five turns like most models do.
I ran a 30-turn debugging session where we traced a race condition through multiple files. The model maintained perfect context throughout. That's impressive.
3. Open-Source Freedom
Released under MIT License. You can:
- Self-host on your infrastructure
- Fine-tune for domain-specific tasks
- Use commercially without restrictions
- Avoid vendor lock-in entirely
4. Modern UI Generation
The Vibe Coding feature is legitimately good. It generates UIs that look contemporary, not like Bootstrap templates from 2015. Proper use of modern CSS, clean layouts, thoughtful color schemes.
5. Multilingual Excellence
66.7% on SWE-bench Multilingual represents a massive +12.9% over its predecessor. If you work with non-English codebases or international teams, this is a significant advantage.
The Not-So-Good Stuff ❌
1. Inference Speed is Middling
Inference efficiency is recorded at 55 tokens per second. This is fine for most tasks but noticeably slower than lightweight models like MiniMax M2 (which hits 150 tokens/sec).
For interactive development, it's acceptable. For batch processing thousands of files, you'll feel the difference.
2. Not Quite Frontier-Level Yet
While GLM-4.7 trades blows with Claude and GPT-4, it's not beating them consistently. On complex reasoning tasks, you'll occasionally hit its limits. It's close, but "close" still means GPT-5 or Claude Opus might be better for your most complex problems.
3. Documentation is Spotty
The official docs are improving but still incomplete in places. Community resources are growing but not yet as comprehensive as OpenAI's or Anthropic's documentation.
Expect some trial and error, especially for advanced features like custom thinking modes or tool integration.
4. API Availability is Fragmented
API access is available through multiple providers (Z.ai, OpenRouter, Novita), but there's no single canonical endpoint. Pricing and features vary by provider, which can be confusing.
5. Model Size Requires Serious Hardware
With 358 billion parameters, running this locally isn't trivial. You need:
- Significant GPU memory (multiple high-end GPUs)
- Proper inference setup (vLLM or SGLang)
- Technical knowledge to optimize
Most users will rely on API access rather than self-hosting.
Real-World Gotchas 🚧
Context Management Matters
That 200K context window is amazing until you realize that using it fully makes each request expensive and slow. Be strategic about what you include.
Thinking Mode Trade-offs
Enabling full thinking mode for every request will balloon your costs and latency. Use turn-level thinking control to balance speed and quality.
Agent Framework Compatibility
While it works with Claude Code and others, some features require specific configurations. Read the integration guides carefully.
Pricing Breakdown: What You'll Actually Pay
Let me break down real-world costs because token pricing means nothing until you see actual usage:
Scenario 1: Side Project Development
Usage: ~500K input tokens, ~200K output tokens per month
Cost: (0.5M × $0.60) + (0.2M × $2.20) = $0.30 + $0.44 = $0.74/month
Compare that to Claude Pro at $20/month or GPT-4 at similar pricing.
Scenario 2: Startup with 5 Developers
Usage: ~50M input tokens, ~20M output tokens per month
Cost: (50 × $0.60) + (20 × $2.20) = $30 + $44 = $74/month
With context caching:
~30% savings: $74 × 0.70 = ~$52/month
That's $10/month per developer for frontier-model-level coding assistance.
Scenario 3: Enterprise Scale
Usage: ~5B input tokens, ~2B output tokens per month
Cost: (5,000 × $0.60) + (2,000 × $2.20) = $3,000 + $4,400 = $7,400/month
With aggressive caching: ~$5,200/month
For context, this level of usage with Claude or GPT-4 would cost $25,000-35,000/month.
Comparison Table: GLM-4.7 vs. The Competition
| Feature | GLM-4.7 | Claude Sonnet 4.5 | GPT-4 Turbo | DeepSeek-V3.2 |
|---|---|---|---|---|
| License | MIT (Open) | Proprietary | Proprietary | Open |
| Parameters | 358B | Unknown | Unknown | 385B |
| Context Window | 200K | 200K | 128K | 128K |
| Max Output | 128K | ~64K | ~4K | ~8K |
| SWE-bench | 73.8% | ~74% | ~70% | ~71% |
| Cost (Input) | $0.60 / M | $3.00 / M | $10.00 / M | $0.60 / M |
| Cost (Output) | $2.20 / M | $15.00 / M | $30.00 / M | $2.80 / M |
| Self-Hostable | ✅ Yes | ❌ No | ❌ No | ✅ Yes |
| Thinking Modes | ✅ Advanced | ✅ Basic | ❌ No | ✅ Basic |
| UI Generation | ✅ Excellent | ✅ Good | ⚠️ Fair | ⚠️ Fair |
| Agent Support | ✅ Native | ✅ Native | ⚠️ Limited | ✅ Native |
The Bottom Line: Should You Use GLM-4.7?
After extensive testing, here's my honest recommendation:
Use GLM-4.7 if:
- You need coding assistance but find Claude/GPT-4 too expensive
- You work on multilingual codebases or international teams
- You value open-source and want to avoid vendor lock-in
- You build agentic workflows and need preserved context
- You care about modern UI generation
- You're a startup or individual developer watching costs
Stick with Claude/GPT-5 if:
- You need the absolute best for critical, complex reasoning tasks
- Cost isn't a concern and you want maximum reliability
- You need comprehensive documentation and support
- You prefer mature, battle-tested infrastructure
Consider other options if:
- You need maximum speed (look at MiniMax M2)
- You want extreme mathematical precision (try DeepSeek-V3.2)
- You're doing non-coding tasks primarily (GPT-4 or Claude might be better)
Final Thoughts
GLM-4.7's release marks a significant democratization of advanced AI capabilities, allowing developers, researchers, and enterprises to self-host and build customized solutions efficiently.
What impresses me most isn't any single benchmark. It's the holistic design—a model that clearly understands how developers actually work. The thinking modes, the preserved context, the UI generation, the multilingual capabilities—these aren't flashy features added for marketing. They solve real problems.
Is it perfect? No. Will it replace your senior developer? Absolutely not. But as a coding copilot that costs a fraction of alternatives and gives you true ownership of your infrastructure? It's genuinely compelling.
This is the first time a GLM model feels like it was trained for actual work, not demos. And that distinction matters.
The landscape of AI coding assistants just got a lot more interesting. GLM-4.7 isn't the most powerful model available, but it might be the most practical for real-world development at scale.
Try it. See if it fits your workflow. At these prices, the experiment costs you basically nothing.

Quick Links & Resources
🔗 Try GLM-4.7:
- Z.ai Chat Interface - Web-based testing
- Hugging Face Model Page - Download weights
- Ollama Library - Easy local setup
🔗 API Access:
- Z.ai API Documentation - Official API
- OpenRouter GLM-4.7 - Multi-provider access
🔗 Pricing & Subscriptions:
- GLM Coding Plans - Developer subscriptions
- Z.ai Pricing - Full pricing details
🔗 Documentation:
- Official Technical Blog - Deep dive
- GitHub Repository - Code & examples
Join the Verse
Get exclusive insights on Next.js, System Design, and Modern Web Development delivered straight to your inbox.
No spam. Unsubscribe at any time.